


The Necessity of Overfitting LLM Applications

In this post I will explain:
How to quickly automate parts of customer service traffic with minimal investment.
Which technology to use for achieving a high ROI on your first automation solution.
The challenges encountered when using AI for the seemingly simple task of email classification.
To create an effective automated customer support solution, it’s essential to view it as a system of interconnected components working seamlessly together.
Previously, we’ve discussed RAG (Retrieval Augmented Generation) and why it is often the preferred choice for automating customer service.
However, a significant challenge remains: many companies lack a well-structured knowledge base. As a result, applying the standard RAG approach—which relies on high-quality data and organized knowledge—becomes difficult.
That said, even without an optimal dataset, the capabilities of modern LLMs (Large Language Models) offer an opportunity to take a crucial first step and achieve two key objectives simultaneously:
Deeply understand your data and evaluate the technical feasibility of automating 20%, 40%, 60%, or even 90% of customer requests.
Implement an initial automation solution that delivers immediate, measurable business impact.
I firmly believe in the “low-hanging fruit” approach. While it may sound like a cliché, my experience shows it builds trust and helps uncover unknowns. You can’t fully anticipate the challenges or benefits until you begin testing and iterating.
For many companies, a significant portion of incoming customer requests are repetitive. While they may not appear so at first glance—since each issue is described differently and reflects the unique perspective of the customer—the underlying problem is often the same.
In my experience, a considerable percentage of these inquiries involve recurring questions that human customer support routinely addresses.
This process, which often requires agents to send standardized responses, is both monotonous and unnecessary given current technological advancements.
Before the advent of LLMs, automating such workflows required training a classification model. Each email would be categorized into a specific topic, and once classified, a predefined template would be used to respond to the customer. This process, while functional, was far more labor-intensive and less adaptable than modern solutions.
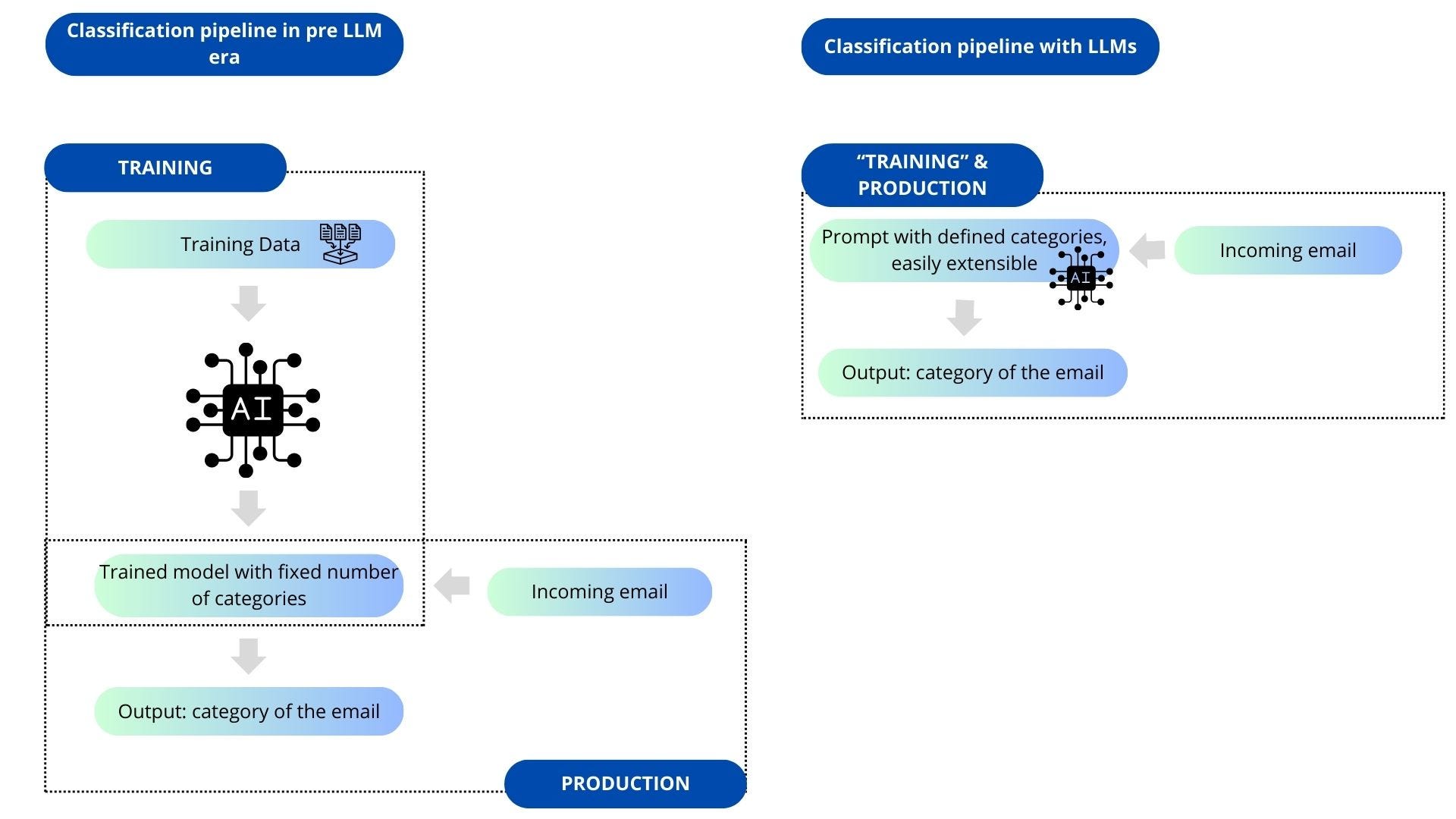
This approach has a relatively low ROI because it requires extensive data collection and annotation. For instance, if you introduce a new feature and customers frequently ask specific questions about it, updating the system is impossible without retraining. Moreover, since this solution is not generative, it remains imperfect and inflexible.
In contrast, LLMs do not have this issue. They excel as zero-shot learners and even more so as few-shot learners. What does this mean? If you explain in prompt which emails fall into a specific category, there's a high chance the LLM will correctly identify the class (one-shot learning). If you provide a few examples of emails that belong to that category, the accuracy increases further (few-shot learning).
This approach works well for most companies, but not all. To assess the potential benefits, you need to look at the data. This fundamental step distinguishes junior AI practitioners from senior ones. Senior practitioners always analyze the data and tailor solutions to the specific situation, while junior engineers often jump straight into the technology. Remember, real gains come from understanding your situation through data analysis and by consulting those who understand the business problem.
By examining the data, we confirmed that a large portion of customer inquiries are repetitive, meaning we could automate part of the traffic without relying on a knowledge base. However, while LLMs are strong few-shot learners, they sometimes overlook critical details.
Let's look at the image to understand the setup.
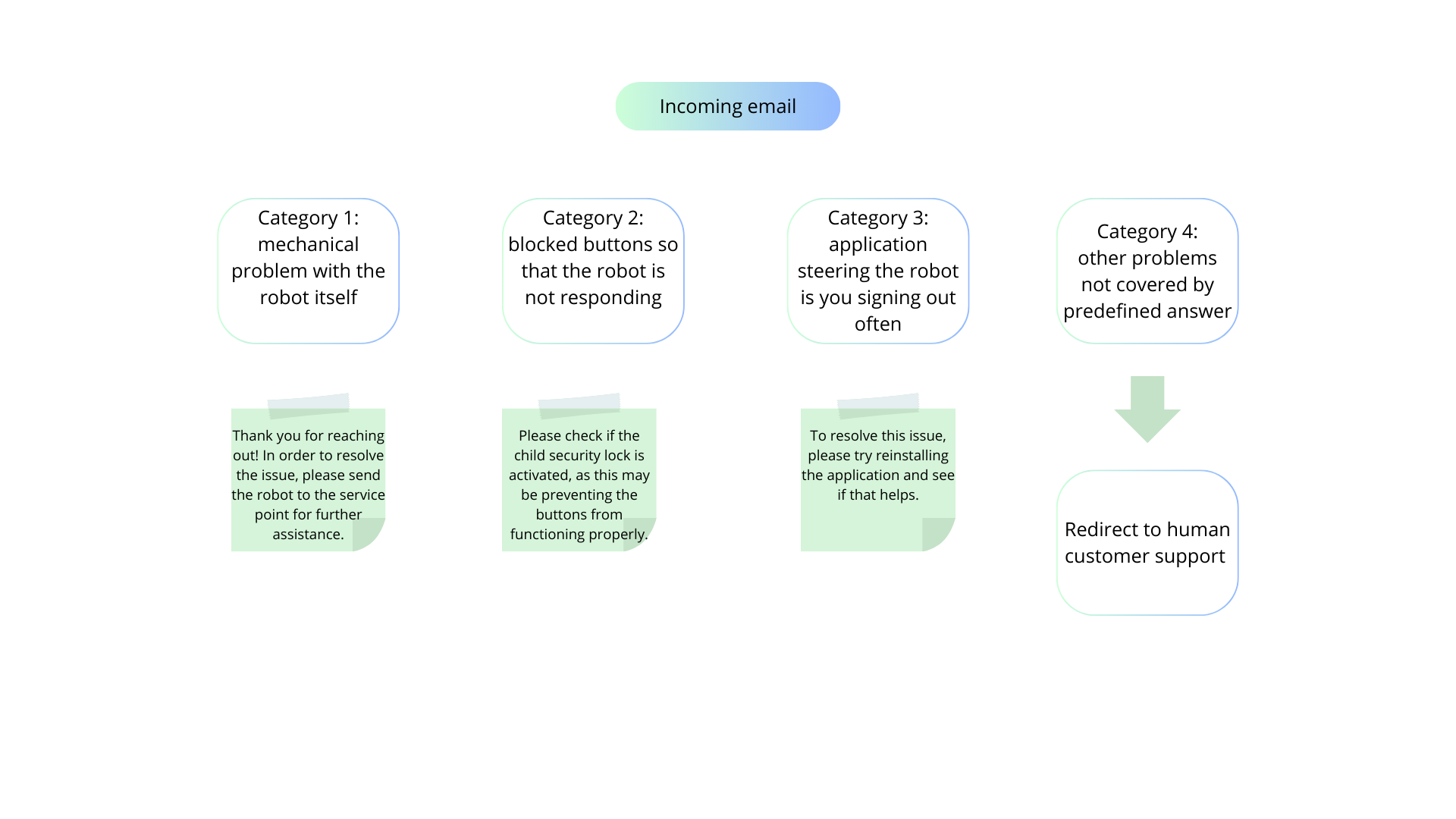
Let's assume we are working for kitchen robot manufacturer - for simplicity of this example, we want to automate emails which concern "malfunctions". Along with the kitchen robot, there is an app which allows you to steer the robot and program it for selected recipes.
Now, by looking at the data, we know that there are several types of popular malfunctions:
mechanical problem with the robot itself -> the robot must be sent to the service point
blocked buttons so that the robot is not responding -> check for child security blockade
application steering the robot is you signing out often -> reinstall application
We will use the following email from a dissatisfied user:
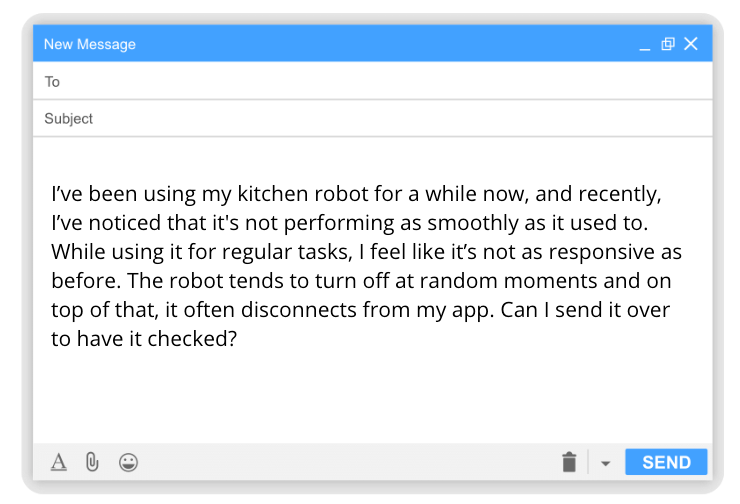
The email has a lot of redundancy and the user is unable to pinpoint the exact problem. Using professional knowledge of the Customer Support Team, we know that this problem is most likely mechanical, and the diagnosis should follow in this direction. There is a small trap in the email - the mention of "app disconnecting". The logic of the email suggests that there is a problem with the robot, not the app itself. We will see that the model falls into this trap.
Now, you will see how fragile and uncertain classification can be. For any application to be practical in a business environment, it must be reliable.
Attempt 1
SIMPLE PROMPTING TECHNIQUE
A simple prompt, written directly from your understanding of the problem, serves as a good starting point. Remember, developing the classification should be done on a representative sample of examples. It t should still perform well for a variety of emails. If you rely on the "looks good to me" approach for evaluation, it might work in tests but fail in production.

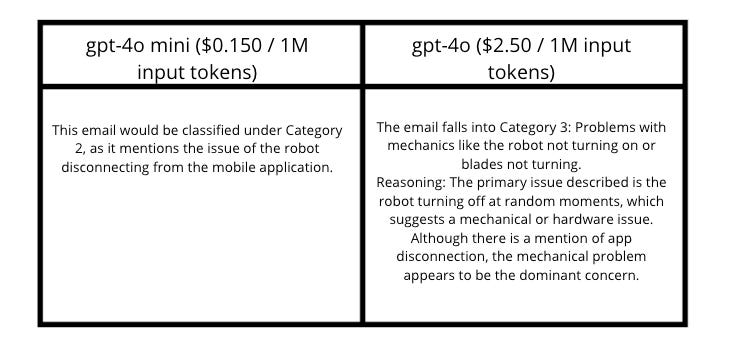
The model - GPT-4o mini (which is a cheaper alternative to GPT-4o and thus more feasible in production) classifies the email to Category 2 and justifies it by saying that "The customer mentions that the robot disconnects from the app frequently, which indicates an issue with the application connectivity."
However, first and foremost, issues with the application should focus on SIGNING OUT, not on the app disconnecting. Secondly, the disconnecting issue is related to broader problems with the robot. The best approach in this case is to categorize it as Category 3 and provide information about servicing.
The above prompt is not top notch, so let's refactor it to be more specific.
Attempt 2
A more refined definition of the categories is needed to better align with the underlying logic and present them in a more descriptive and fluent manner.

Once again, GPT-4o mini classifies it as Category 2. However, GPT-4o selects Category 3 with sound reasoning. Unfortunately, due to cost constraints, we need to stick with GPT-4o mini and make it work.
Attempt 3
As we can clearly see, the issues arise from the mention of "robot disconnecting from the app" in the email. To address this, we may need to be more explicit about the types of emails that fall under this category. To this end, we will provide concrete examples of phrases that the model should look for and clearly define that this category only applies to issues directly related to signing out of the application.
Attention: This example is very fragile—it may classify as either Category 4 or Category 3, depending on the run: ChatGPT example

This time, the email was classified as Category 4 with the following explanation. This is actually quite interesting, as the email explicitly mentions issues with the robot turning off, and one would expect that the examples we provided for Category 3 would lead the model to select it instead.
Response from GPT-4o mini: "The email should be classified under Category 4: Other, as it does not specifically mention issues related to blocked buttons, automatic sign-outs from the mobile application, or mechanical problems with the robot (such as not turning on or blades not turning). Instead, it addresses a general issue with performance and disconnections from the app."
As I mentioned earlier, this example is fragile, and when I ran it a second time, the email was correctly classified as Category 3. This is due to a parameter in LLMs called "temperature," which determines the level of creativity in the output. A higher temperature encourages more creative and varied responses, while a lower temperature leads to more deterministic and repetitive outcomes.
These examples are inspired by real-life situations but are intended for illustrative purposes only. In practice, I have struggled with crafting prompts for the correct classification of incoming emails, as customers often use creative language to describe their issues. It reached a point where I had to explicitly define forbidden and allowed phrases within the class definition.
In spite of the "intelligence" of the generative models, they often tend to take shortcuts - seeing a category about an "app", they tend to classify all texts mentioning "app" to this category. That is why the prompts must be very decisive in defining which kinds of "apps" should really be classified.
This is why, even though we are not training the model in the traditional sense when using LLMs, it is still very easy to overfit to the sample we are developing a prompt on. The old rules still apply: develop the prompt on a training set and always reserve a representative test set.