
Graph RAG in Customer Service - beyond the buzz (Part 1: Community Summaries)
What specific benefits do Graph RAGs offer to Customer Support? Let's find out on real examples.

Graph RAGs are all the rage now. From the business perspective, they hold the potential to enhance the quality of traditional RAG systems, delivering more accurate and contextually relevant answers to users. However, how this would work in real-world settings remains unclear. During our investigation, we found that most articles and tutorials on the subject were vague. The examples provided were often generic (“Paris IS_A city”) rather than demonstrating concrete benefits over traditional RAG systems through case studies. In this post, I provide observations based on experiments on real customer support data.
The theory of Graph RAG seems promising, especially given that we’re working on technical customer support. Our systems are usually based on documentations, manuals and blogposts, in particular about electronic devices. Such data has a deep structural logic of how the devices work, regarding both their internal construction and cooperation with other systems. So, a graph structure seems like a logical choice.
Graph RAG systems are quite complex, but the main idea is to detect entities and their relationships in text chunks. This allows to build an interconnected structure (a graph), where some entities (and by proxy, their corresponding chunks) are more strongly connected than others, building communities. Community detection is done using classic graph algorithms such as Leiden algorithm. After detection, it is possible to summarize the contents of each community using an LLM. The Community Summaries are an important feature of a Graph RAG retrieval system (however, in a full-blown Graph RAG, they are just one of many multi-level sources of information).
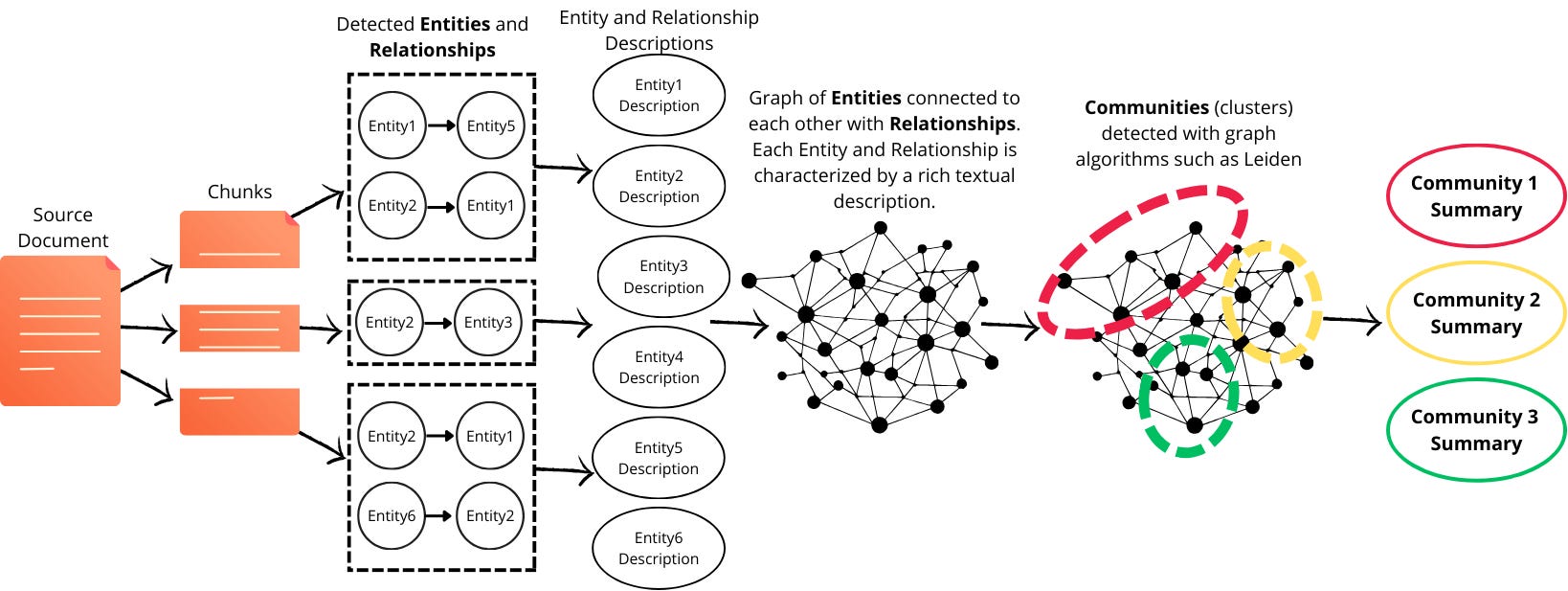
In this post, I focus specifically on Community Summaries and their potential role in a technical customer support RAG system. What unique value can they provide compared to a traditional RAG? Can they uncover insights that a standard RAG system cannot?
Although I observed some promising results, we don’t have such a system in production. We need more data to determine whether these improvements will be consistently achievable—particularly when factoring in the increased processing costs associated with Graph RAG systems.
Technical setting
I use a basic Graph RAG setup with LlamaIndex, similar to the one described in the post: https://docs.llamaindex.ai/en/stable/examples/cookbooks/GraphRAG_v1/
I chose to experiment with LlamaIndex primarily because “pro” graph databases like Neo4j often come with a steep learning curve for many AI practitioners. While LlamaIndex offers only basic support for Graph RAGs, it is sufficient for studying graph communities. However, it currently lacks a convenient set of building blocks for full-fledged Graph RAG systems. Developing a complete Graph RAG solution requires a different implementation approach, which I will explore in future posts.
As my experimental dataset, I downloaded texts about Thermomix from their official site - https://www.thermomix.com/ - mainly texts from their Help Center and manuals.
What do Community Summaries give us?
FYI (this will be important for understanding our experiments): Scaling in Thermomix refers to the new feature in Cookidoo that allows users to adjust recipe serving sizes to suit their needs.
Overall, Community Summaries tend to have a few interesting properties:
1. They normalize entity names
Instead of using variations like “scaling”, “scaled recipes”, “Scaling”, and other similar forms, they tend to stick to a detected entity name “Scaling” in all summaries. This potentially makes it easier to recognize a certain entity in text - as LLMs don’t need to determine whether different wordings refer to the same concept or carry distinct meanings. For example:
Source text (among others, since Community Summaries are built using multiple chunks):
“To access scaled recipes on Cookidoo, you must upgrade your membership to version 3.0.”
Community Summary:
“The relationship between "Annual Membership" and "Scaling" on the Cookidoo platform is centered around access privileges. Specifically, the Annual Membership is essential for users to utilize the Scaling feature. This indicates that by upgrading their membership, users gain the capability to access and benefit from this particular feature.”
2. They have a predictable, consistent structure
The summaries usually begins with the introduction of 2 or more entities which are (inter)connected, then define the nature of each connection. They contain fairly small amounts of free text. Mostly, the sentence format follows the structure “X does/is/<another verb> Y”. Here’s another example with more entities involved:
Community Summary:
“The relationships outlined highlight the connections between Cookidoo, Thermomix, and the Thermomix Cutter, emphasizing Cookidoo's role as a central recipe platform.
Cookidoo and Membership: Cookidoo offers a membership service that grants users access to its extensive features and recipes, enhancing the cooking experience.
Cookidoo as a Recipe Source: Cookidoo serves as a dedicated recipe source for Thermomix users, providing tailored recipes that cater to various models of the Thermomix appliance.
Cookidoo and Thermomix Cutter: Cookidoo also provides recipes specifically designed for the Thermomix Cutter, showcasing its commitment to supporting users of this particular kitchen appliance.”
What is the influence on final RAG answers?
From what I’ve seen, the main use of Community Summaries is providing better, alternative contexts to the final generator LLM. Combined with graph traversal (which I don’t do in this post, but will describe later), the context base returned by the graph retrieval can be pretty large, but still pretty relevant. For example, let's ask the question:
“Why can't I use scaling?”
A traditional RAG returns an answer from one of the Help Center FAQ-like articles:
“You cannot use the scaling feature because it is only available with an upgraded annual Cookido membership. To access scaled recipes, you need to upgrade to version 3.0.”
However, the Graph RAG answer goes a bit deeper:
“Membership Limitations: If you are not a member of Cookidoo, you may not have access to all features, including scaling. Ensure that your membership is active and that you are logged in.
Recipe Compatibility: Not all recipes on Cookidoo may support scaling. Some recipes, especially those tailored for specific Thermomix models or the Thermomix Cutter, might have limitations on how they can be adjusted.
Technical Issues: There could be a temporary technical issue with the Cookidoo platform. If you are experiencing problems, try refreshing the page or checking for updates.”
Thanks to the Community Summaries which often gather multiple interconnected entities in the same summary, it is possible to detect that the app Cookidoo can indeed provide Scaled recipes, but also provides dedicated recipes to specific Thermomix models:
Cookidoo as a Recipe Source: Cookidoo serves as a dedicated recipe source for Thermomix users, providing tailored recipes that cater to various models of the Thermomix appliance.
So, the recipe might be unsuitable for our device, or the app itself can be to blame.
Conclusion?
Generally, there are 2 main advantages of using Graph RAG Community Summaries for our problem:
More structured and normalized contexts as an alternative information source during retrieval.
Ability to gather multiple entities into one Community Summary sometimes allows to see what influence the RELATED structures/systems might have on the problem our user is facing.
A full-blown Graph RAG also contains other interesting features, such as graph traversal, which allows to reach linked entities. Their descriptions can then be used as additional contexts, which is useful in some scenarios. I will describe this in the next posts.