
A real-life framework for RAG evaluation: beyond the 'Looks-Good-to-Me' Metric
Insights from evaluating working application with noisy and messy data.

Evaluation of RAG systems might seem straightforward in theory, but in practice it's one of the most challenging aspects of building generative AI systems, especially in real-world applications like customer support where data is noisy. Many discussions on RAG evaluation center around two primary components:
Retrieval Accuracy – Measuring the percentage of times the system retrieves the correct context required to answer a given question.
Generation Quality – Assessing the correctness and relevance of generated responses, usually with another LLM as a judge.
However, considering that questions asked by customers are very diversified and the source of knowledge can come from not standard data sources (link do click&create), implementation is far from trivial. That is why it is tempting to rely on a "looks-good-to-me" evaluation metric, which is subjective, inconsistent, and leads to misleading conclusions. Instead, a structured approach to RAG evaluation must be adopted, ensuring rigorous testing and validation before the system is deployed.
To be honest, if the team does not want to spend time on developing a solid evaluation framework, I do not want to work on a project. I have seen it many times so far and learnt from my mistake - without proper evaluation you enter a vicious circle of never-ending improvements without a clear understanding of the usefulness of the system. No, thank you.
In this article I am proposing a framework which is:
down to earth
considers the specifics of your data
and is time boxed so you can propose a concrete way forward for your team and have other stakeholders on board.
By following this five-week structured approach—three weeks for experimentation, two weeks for dataset creation, and one week for judge calibration—we ensure that we build a reliable and scalable evaluation framework. This is the way to move beyond the flawed "looks-good-to-me" metric and towards a robust, production-ready RAG system.
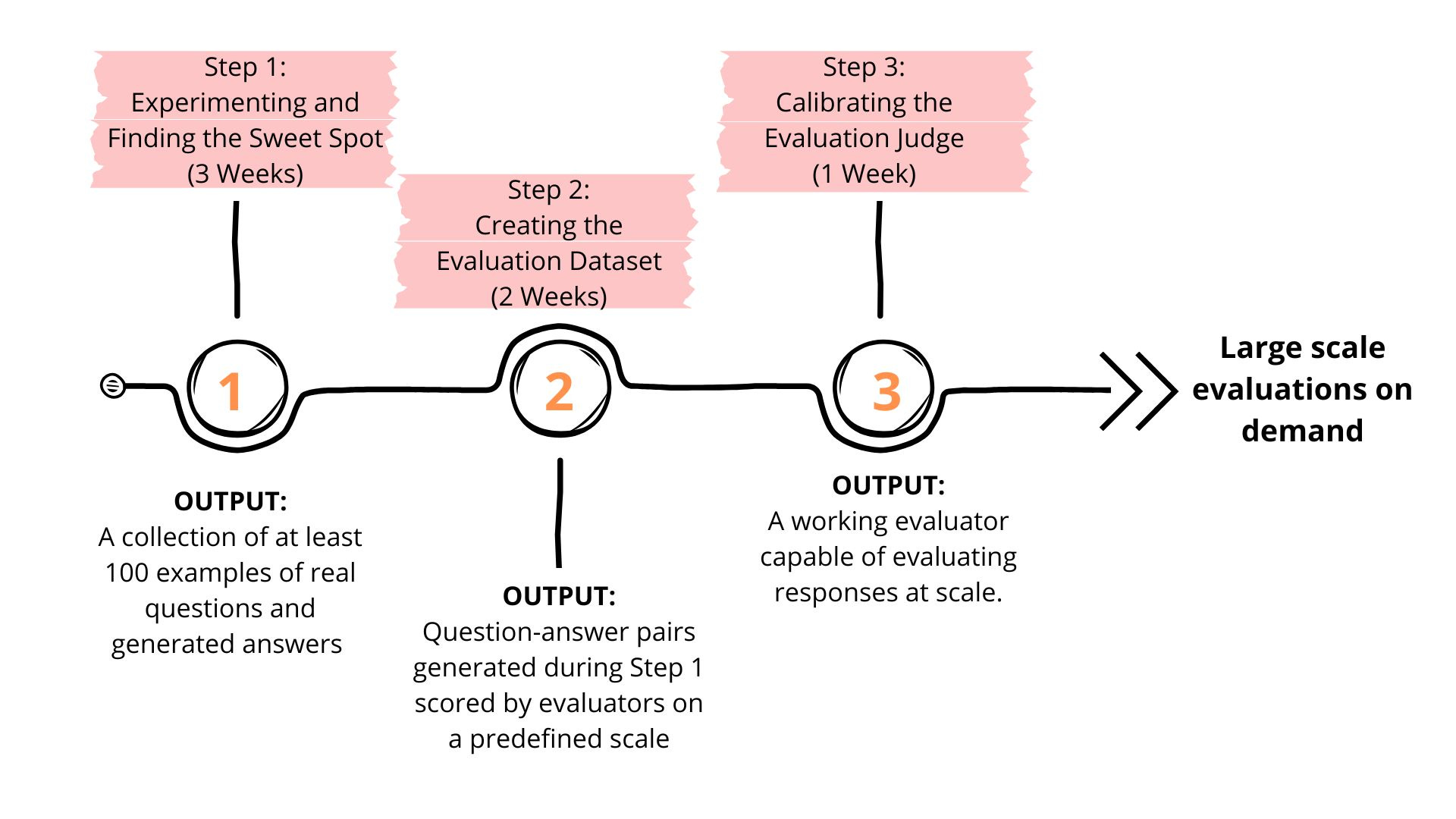
Step 1: Experimenting and Finding the Sweet Spot (3 Weeks)
Before conducting a formal evaluation, technical teams should experiment with various configurations to establish a baseline level of acceptable performance. The outputs from this phase are not intended to be production-ready. The primary goal is to generate results that can be reviewed by the evaluation team, allowing them to assess response quality. Since you will be "training" your evaluator on these responses, it's crucial to present a diverse range of questions.
During this stage it is critical to avoid presenting extremely poor outputs to business stakeholders, because you will have a biased evaluation.
This phase is a standard part of any development process, and the insights gained will inform the final solution. The key distinction here is knowing when to transition to Step 2—many teams continue iterating indefinitely, ultimately relying on the subjective "looks good to me" metric described earlier. Sometimes, the teams will pick a few examples which are "not working" and try to fix them - damaging performance on the majority of data.
That's why the experimental phase should last up to three weeks—no more. Extending it beyond this point risks reliance on subjective assessment. The goal is to reach a point where responses are "good enough"—not perfect, but coherent and somewhat logical. At this stage, we acknowledge that we don’t yet have a concrete quality measure, but we can confirm that responses are not nonsensical.
Output of this phase: a collection of at least 100 examples of real questions and generated answers
Step 2: Creating the Evaluation Dataset (2 Weeks)
Many teams make the critical mistake of skipping this phase or generating synthetic datasets, which often fail to reflect real-world usage. Instead, we must gather actual user queries from real-life scenarios. If we are building a customer support agent, we should extract authentic customer inquiries rather than generating artificial ones. The challenge here is that we often do not have the correct ground-truth answers readily available. Answers can differ significantly between human agents, making evaluation even more complex. To address this, a dedicated two-week period should be allocated to creating a high-quality evaluation dataset. If stakeholders refuse to allocate this time, the project is unlikely to succeed.
The output of the previous step serves as an input for this phase. In GenAI evaluation we are stepping aside from asking evaluators to provide real - ground truth - answers. That would be time-consuming and not scalable at all. Instead, human evaluators must judge the outputs on a scale you find useful for your project. I propose something like what META introduced during its RAG challenge CRAG - it is useful and serves as a good starting point for many evaluations:
Perfect. The response correctly answers the user’s question and contains no hallucinated content.
Acceptable. The response provides a useful answer to the user’s question but may contain minor errors that do not harm the usefulness of the answer.
Missing. The response is “I don’t know”, “I’m sorry I can’t find ...”, a system error such as an empty response, or a request from the system to clarify the original question.
Incorrect. The response provides wrong or irrelevant information to answer the user’s question.
Without a solid dataset, we lack an objective benchmark and risk falling into a never-ending cycle of subjective assessments. Having a well-defined dataset allows us to:
Avoid overfocusing on a handful of cherry-picked queries.
Additionally, it helps in gaining a better understanding of the different types of questions, which, in a successful RAG application, are managed separately by specialized LLM agents. Overall, this approach is valuable not only for evaluation but also for making targeted improvements to the system.
Output: Question-answer pairs generated during Step 1 scored by evaluators on a predefined scale.
Step 3: Calibrating the Evaluation Judge (1 Week)
In this step, we are using human evaluation to adjust our evaluation system which we call a judge, so that it can mimic human grading. Here’s how:
Create a scoring prompt that instructs the LLM to evaluate texts using the same scale as human evaluators. Keep in mind that this process is more of an art than a science, so don’t be discouraged if it doesn’t work perfectly on the first attempt.
Use 50 of these graded responses for calibration, meaning that scored generated by LLM Judge must be correlated with human grading. We do not actually train any model here, we just find prompt which output in a form of scores correlates with scores provided by evaluators. So if evaluator scored response as 1, LLM should also output 1.
Use the remaining 50 to verify that the calibration generalizes well.
By doing this, we ensure that the evaluation judge learns how humans assess quality, allowing us to scale the evaluation process beyond just 100 queries. This prevents overfitting and ensures that our automated evaluation remains aligned with human judgment.
Output: a working evaluator capable of evaluating responses at scale.
Running Large-Scale Evaluation
With a calibrated evaluation judge, we can now assess system performance at scale. This enables us to:
Measure retrieval effectiveness across thousands of queries.
Evaluate generation quality with consistency.
Identify specific failure cases systematically.
At this stage, we can be confident that our evaluation is objective, structured, and repeatable.
One of the biggest pitfalls in RAG projects is failing to create an evaluation dataset early. Many teams remain stuck in an endless cycle of subjective assessment, never reaching a structured evaluation phase.
The key takeaway is: Have the discipline to stop experimenting after three weeks and transition to structured evaluation. Without this discipline, the project is doomed to failure, leading to endless delays and dissatisfaction from stakeholders.